May 16th, 2005 — 12:00am
Thursday night I was at Casablanca in Harvard Square for an information architecture meet and greet after Lou’s Enterprise IA seminar. I ordered a Wolver’s. It was dim and noisy, so after shouting three times and pointing, I ended up with a Wolaver’s…
Not a surprise, right? My first thought was “What’s in my glass?” My second thought – I was surrounded by information architects – was about the semantic angle on the situation. It seems like a fair mistake to make in a loud and crowded bar. But as someone who works there, he should know the environmental context, the ways it affects fundamental tasks like talking and answering questions, and about any alternatives to what he thought I said that are close enough to be easily mistaken. Before I get too far, I’ll point out that I liked the mistake enough to order another.
Setting aside for a moment the notion of a semantically adept agent system that monitors interactions between bartenders and patrons to prevent mistakes like this, let’s look at something more likely, such as how does Google fair with this situation? Some post-socialization research shows that as far as Google is concerned, all roads do in fact lead to Wolaver’s. Even when Google’s results list begins with a link to a page on Wolver’s Ale from the originating brewery, it still suggests that you might want ‘wolaver’s ale’. Maybe this explains the bartender’s mistake.
Here’s the breakdown: Google US suggests “wolaver’s ale” when you search for “wolvers ale” and “wolver’s ale”, but not the other way around. When you search for “Wolavers”, Google suggests the correctly punctuated “Wolaver’s”. You can get to the American ale, but not the British.
More surprising, it’s the same from Google UK, when searching only British pages. (Someone tell me how pages become part of the UK? Maybe when they’re sent off to full-time boarding school?)
Google’s insistence on taking me from wherever I start to “Wolaver’s Ale” comes from more than simple American brew chauvanism. This is what happens when the wrong factors drive decisions about the meanings of things; it’s these basic decisions about semantics that determine whether or not a thing correctly meet the needs of the people looking for answers to a question.
You might say semantic misalignment (or whatever we choose to call this condition) is fine, since Google’s business is aimed at doing something else, but I can’t imagine that business leaderhsip and staff at Wolver’s would be too happy to see Google directing traffic away from them by suggesting that people didn’t want to find them in the first place. Neither Wolver’s nor Wolavers seems to have Google ads running for their names, but what if they did? By now we’re all familar with the fact that googling ‘miserable failure‘ returns a link to the White House web site. This reflects a popularly defined association rich in cultural significance, but that isn’t going to satisfy a paying customer who is losing business because a semantically unaware system works against them.
This a good example of a situation in which intelligent disambiguation based on relationships and inferencing within a defined context has direct business ramifications.
Here’s a preview of the full size table that shows the results of checking some variants of wolvers / wolavers:

Related posts:
Comment » | Semantic Web
April 25th, 2005 — 12:00am
Reading the online edition of the New York Times just before leaving work this afternoon, I came across an ironic mistake that shows the utility of a well developed semantic framework that models the terms and relationships in defingin different editorial contexts. In an article discussing the Matrix Online multiplayer game, text identifying the movie character the Oracle mistakenly linked to a business profile page on the company of the same name. In keeping with the movie’s sinister depictions of technology as a tool for creating deceptive mediated realities, by the time I’d driven home and made mojitos for my visiting in-laws, the mistake was corrected…
Ironic humor aside, it’s unlikely that NYTimes Digital editors intended to confuse a movie character with a giant software company. It’s possible that the NYTimes Digital publishing platform uses some form of semantic framework to oversee automated linking of terms that exist in one or more defined ontologies, in which case this mistake implies some form of mis-categorization at the article level,invokgin the wrong ontology. Or perhaps this is an example of an instance where a name in the real world exists simultaneously in two very different contexts, and there is no semantic rule to govern how the system handles reconciliation of conflicts or invocation of manual intervention in cases when life refuses to fit neatly into a set of ontologies. That’s a design failure in the governance components of the semantic framework itself.
It’s more likely that the publishing platform automatically searches for company names in articles due for publication, and then creates links to the corresponding profile information page without reference to a semantic framework that employs contextual models to discriminate between ambiguous or conflicting term usage. For a major content creator and distributor like the NY Times, that’s a strategic oversight.
In this screen capture, you can see the first version of the article text, with the link to the Oracle page clearly visible:
Mistake:
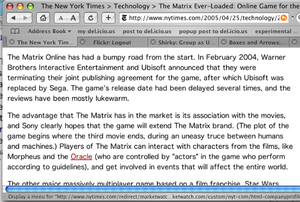
The new version, without the mistaken link, is visible in this screen capture:
New Version:
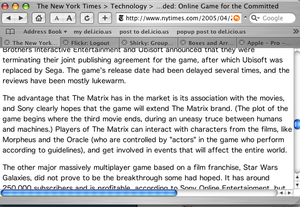
Related posts:
Comment » | Semantic Web
February 8th, 2005 — 12:00am
rdfdata.org offers a great collection of RDF data sets and services that generate RDF.
Related posts:
Comment » | Semantic Web
May 3rd, 2004 — 12:00am
Here’s a some snippets from an article in the Web Services Journal that nicely explains some of the business benefits of a services-based architecture that uses ontologies to integrate disparate applications and knowledge spaces.
Note that XML / RDF / OWL – all from the W3C – together only make up part of the story on new tools for how making it easy for systems (and users, and businesses…) to understand and work with complicated information spaces and relationships. There’s also Topic Maps, which do a very good job of visually mapping relationships that people and systems can understand.
Article:Semantic Mapping, Ontologies, and XML Standards
The key to managing complexity in application integration projects
Snippets:
Another important notion of ontologies is entity correspondence. Ontologies that are leveraged in more of a B2B environment must leverage data that is scattered across very different information systems, and information that resides in many separate domains. Ontologies in this scenario provide a great deal of value because we can join information together, such as product information mapped to on-time delivery history mapped to customer complaints and compliments. This establishes entity correspondence.
So, how do you implement ontologies in your application integration problem domain? In essence, some technology – either an integration broker or applications server, for instance – needs to act as an ontology server and/or mapping server.
An ontology server houses the ontologies that are created to service the application integration problem domain. There are three types of ontologies stored: shared, resource, and application. Shared ontologies are made up of definitions of general terms that are common across and between enterprises. Resource ontologies are made up of definitions of terms used by a specific resource. Application ontologies are native to particular applications, such as an inventory application. Mapping servers store the mappings between ontologies (stored in the ontology server). The mapping server also stores conversion functions, which account for the differences between schemas native to remote source and target systems. Mappings are specified using a declarative syntax that provides reuse.
RDF uses XML to define a foundation for processing metadata and to provide a standard metadata infrastructure for both the Web and the enterprise. The difference between the two is that XML is used to transport data using a common format, while RDF is layered on top of XML defining a broad category of data. When the XML data is declared to be of the RDF format, applications are then able to understand the data without understanding who sent it.
Comment » | Semantic Web