Lets build on the analysis of tag clouds from Tag Clouds Evolve: Understanding Tag Clouds, and look ahead at what the near future may hold for second generation tag clouds (perhaps over the next 12 to 18 months). As you read these predictions for structural and usage changes, keep two conclusions from the previous post in mind: first, adequate context is critical to sustaining the chain of understanding necessary for successful tag clouds; second, one of the most valuable aspects of tag clouds is as visualizations of semantic fields.
Based on this understanding, expect to see two broad trends second in generation tag clouds.
In the first instance, tag clouds will continue to become recognizable and comprehensible to a greater share of users as they move down the novelty curve from nouveau to known. In step with this growing awareness and familiarity, tag cloud usage will become:
1. More frequent
2. More common
3. More specialized
4. More sophisticated
In the second instance, tag cloud structures and interactions will become more complex. Expect to see:
1. More support for cloud consumers to meet their needs for context
2. Refined presentation of the semantic fields underlying clouds
3. Attached controls or features and functionality that allow cloud consumers to directly change the context, content, and presentation of clouds
Together, these broad trends mean we can expect to see a second generation of numerous and diverse tag clouds valued for content and capability over form. Second generation clouds will be easier to understand (when designed correctly…) and open to manipulation by users via increased functionality. In this way, clouds will visualize semantic fields for a greater range of situations and needs, across a greater range of specificity, in a greater diversity of information environments, for a greater number of more varied cloud consumers.
Usage Trends
To date, tag clouds have been applied to just a few kinds of focuses (links, photos, albums, blog posts are the more recognizable). In the future, expect to see specialized tag cloud implementations emerge for a tremendous variety of semantic fields and focuses: celebrities, cars, properties or homes for sale, hotels and travel destinations, products, sports teams, media of all types, political campaigns, financial markets, brands, etc.
From a business viewpoint, these tag cloud implementations will aim to advance business ventures exploring the potential value of aggregating and exposing semantic fields for a variety of strategic purposes:
1. Creating new markets
2. Understanding or changing existing markets
3. Providing value-added services
4. Establishing communities of interest / need / activity
5. Aiding oversight and regulatory imperatives for transparency and accountability.
Measurement and Insight
I think tag clouds will continue to develop as an important potential measurement and assessment vehicle for a wide variety of purposes; cloudalicious is a good example of an early use of tag clouds for insight. Other applications could include using tag clouds to present metadata in geospatial or spatiosemantic settings that combine GPS / GIS and RDF concept / knowledge structures.
Within the realm of user experience, expect to see new user research and customer insight techniques emerge that employ tag clouds as visualizations and instantiations of semantic fields. Maybe even cloud sorting?
Clouds As Navigation
Turning from the strategic to the tactical realm of experience design and information architecture, I expect tag clouds to play a growing role in the navigation of information environments as they become more common. Navigational applications comprise one of the first areas of tag cloud application. Though navigation represents a fairly narrow usage of tag clouds, in light of their considerable potential in reifying semantic fields to render them actionable, I expect navigational settings will continue to serve as a primary experimental and evolutionary venue for learning how clouds can enhance larger goals for information environments such as enhanced findability.
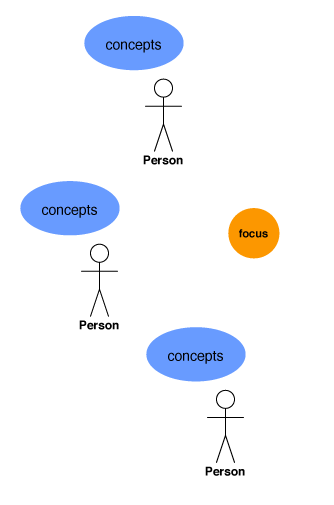
For new information environments, the rules for tag clouds as navigation components are largely unwritten. But many information environments already have mature navigation systems. In these settings, tag clouds will be one new type of navigation mechanism that information architects and user experience designers integrate with existing navigation mechanisms. David Fiorito’s and Richard Dalton’s presentation Creating a Consistent Enterprise Web Navigation Solution is a good framework / introduction for questions about how tag clouds might integrate into mature or existing navigation systems. Within their matrix of structural, associative and utility navigation modes that are invoked at varying levels of proximity to content, tag clouds have obvious strengths in the associative mode, at all levels of proximity to content, and potential strength in the structural mode. Figure 1 shows two tag clouds playing associative roles in a simple hypothetical navigation system.
Figure 1: Associative Clouds

I also expect navigation systems will feature multiple instances of different types of tag clouds. Navigation systems employing multiple clouds will use combinations of clouds from varying contexts (as flickr and technorati already do) or domains within a larger information environment to support a wide variety of purposes, including implicit and explicit comparison, or views of the environment at multiple levels of granularity or resolution (high level / low level). Figure 2 illustrates multiple clouds, Figure 3 shows clouds used to compare the semantic fields of a one focus chosen from a list, and Figure 4 shows a hierarchical layout of navigational tag clouds.
Figure 2: Multiple Clouds

Figure 3: Cloud Comparison Layout

Figure 4: Primary / Secondary Layout

Structural and Behavioral Trends
Let’s move on to consider structural and behavioral trends in the second generation of tag clouds.
Given the success of the simple yet flexible structure of first generation tag clouds, I expect that second generation clouds will not substantially change their basic structure. For example, tag clouds will not have to change to make use of changing tagging practices that enhance the semantic depth and quality of tags applied to a focus, such as faceted tagging, use of qualifiers, hierarchical tagging, and other forms. James Melzer identifies some best practices on del.icio.us that make considerable sense when the focus of a semantic field is a link. His recommendations include:
- Source your information with via:source_name or cite:source_name
- Create a parent categories, and thus a rudimentary hierarchy, with parent_tag/subject_tag
- Mention publications names with in:publication_name
- Flag the type of resource with .extension or =resource_type
- Use a combination of general and specific tags on every bookmark to provide both clustering and differentiation
- Use synonyms or alternate forms of tags
- Use unique or distinctive terms from documents as tags (don’t just use major subject terms)
The two element structure of first generation tag clouds can accommodate these tagging practices. However, with a semantic field of greater depth and richness available, the interactions, behaviors, and presentation of tag clouds will evolve beyond a static set of hyperlinks.
Cloud consumers’ need for better context will drive the addition of features and functionality that identify the context of a tag cloud explicitly and in detail. For example, clouds created by a defined audience will identify that audience, whether it be system administrators, freelance web designers, DJ’s, or pastry chefs rating recipes and cooking equipment and provide indication of the scope and time periods that bound the set of tags presented in the cloud. Flickr and others do this already, offering clouds of tags covering different intervals of time to account for the changing popularity of tags over their lifespan.
Moving from passive to interactive, tag clouds will allow users to change the cloud’s semantic focus or context with controls, filters, or other parameters (did someone say ‘sliders’ – or is that too 5 minutes ago…?). I’ve seen several public requests for these sorts of features, like this one: “It would be great if I could set preferences for items such as time frame or for tags that are relevant to a particular area etc or even colour the most recent tags a fiery red or remove the most recent tags.” Figure 5 shows a tag cloud with context controls attached.
Figure 5: Context Controls

Figure 6: Behavior Controls

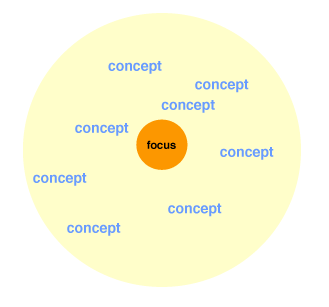
Diversifying consumer needs and goals for way finding, orientation, information retrieval, task support, product promotion, etc., will bring about inverted tag clouds. Inverted tag clouds will center on a tag and depict all focuses carrying that tag.
Figure 7: Inverted Clouds Show Conceptually Related Focuses

In the vein of continued experiment, tag clouds will take increased advantage with RIA / AJAX and other user experience construction methods. Following this, tag clouds may take on some of the functions of known navigation elements, appearing as sub-menus / drop down menus offering secondary navigation choices.
Figure 8: Clouds As Drop Menus

Along the same lines, tag clouds will demonstrate more complex interactions, such as spawning other tag clouds that act like magnifying lenses. These overlapping tag clouds may offer: multiple levels of granularity (a general view and zoom view) of a semantic field; thesaurus style views of related concepts; parameter driven term expansion; common types of relationship (other people bought, by the same author, synonyms, previously known as, etc.)
Figure 9: Magnifying Clouds
Genres
Looking at the intersection of usage and behavior trends, I expect tag clouds will evolve, differentiate, and develop into standard genres. Genres will consist of a stable combination of tag cloud content, context, usage, functionality, and behavior within different environments. The same business and user goals that support genres in other media and modes of visualization will drive the development of these tag cloud genres. One genre I expect to see emerge shortly is the search result.
Conclusions
Reading over the list, I see this is an aggressive set of predictions. It’s fair to ask if I really have such high expectations for tag clouds? I can’t say tag clouds will take over the world, or even the Internet. But I do believe that they fill a gap in our collective visualization toolset. The quantity, quality, and relevance of semantic information in both real and virtual environments is constantly increasing. (In fact, the rate of increase is itself increasing, though that is a temporary phenomenon.) I think tag clouds offer a potential to quickly and easily support the chain of understanding that’s necessary for semantic fields across diverse kinds of focuses. There’s need for that in many quarters, and I expect that need to continue to grow.
For the moment, it seems obvious that tag clouds will spend a while in an early experimental phase, and then move into an awkward adolescent phase, as features, applications and genres stabilize in line with growing awareness and comfort with clouds in various settings.
I expect these predictions to be tested by experiments will play out quickly and in semi or fully public settings, as in the example of the dialog surrounding 83 degrees usage of a tag cloud as the sole navigation mechanism on their site that Rashmi Sinha’s post The tag-cloud replaces the basic menu – Is this a good idea? kicked off recently.
My answer to this question is that replacing all navigation menus with a tag cloud is only a good idea under very limited circumstances. It’s possible that 83 Degrees may be one of these limited instances. Startups can benefit considerably from any positive attention from the Web’s early adopter community (witness Don’t Blow Your Beta by Michael Arrington of Techcrunch).
The page’s designer said, “In this case it was done as a design/marketing effort and not at all for UI”. Since attracting attention was the specific purpose, I think the result is a success. But it’s still an experimental usage, and that’s consistent with the early stage of evolution / development of tag clouds in general.
I’m looking forward to what happens next…