May 31st, 2005 — 12:00am
Concept maps popped onto the radar last week when an article in Wired highlighted a concept mapping tool called Cmap. Cmap is one of a variety of concept mapping tools that’s in use in schools and other educational settings to teach children to model the structure and relationships connecting – well – concepts.
The root idea of using concept mapping in educational settings is to move away from static models of knowledge, and toward dynamic models of relationships between concepts that allow new kinds of reasoning, understanding, and knowledge. That sounds a lot like the purpose of OWL.
It might be a stretch to say that by advocating concept maps, schools are in fact training kids to create ontologies as a basic learning and teaching method, and a vehicle for communicating complex ideas – but it’s a very interesting stretch all the same. As Information Architects, we’re familiar with the ways that structured visualizations of interconnected things – pages, topics, functions, etc. – communicate complex notions quickly and more effectively than words. But most of the rest of the world doesn’t think and communicate this way – or at least isn’t consciously aware that it does.
It seems reasonable that kids who learn to think in terms of concept maps from an early age might start using them to directly communicate their understandings of all kinds of things throughout life. It might be a great way to communicate the complex thoughts and ideas at play when answering a simple question like “What do you think about the war in Iraq?”
Author Nancy Kress explores this excact idea in the science fiction novel ‘Beggars In Spain’, calling the constructions “thought strings”. In Kress’ book, thought strings are the preferred method of communcation for extremely intelligent genetically engineered children, who have in effect moved to realms of cognitive complexity that exceed the structural capacity of ordinary languages. As Kress describes them, the density and multidimensional nature of thought strings makes it much easier to share nuanced understandings of extremely complex domains, ideas, and situations in a compact way.
I’ve only read the first novel in the trilogy, so I can’t speak to how Kress develops the idea of thought strings, but there’s a clear connection between the construct she defines and the concept map as laid out by Novak, who says, “it is best to construct concept maps with reference to some particular question we seek to answer or some situation or event that we are trying to understand”.
Excerpts from the Wired article:
“Concept maps can be used to assess student knowledge, encourage thinking and problem solving instead of rote learning, organize information for writing projects and help teachers write new curricula. “
“We need to move education from a memorizing system and repetitive system to a dynamic system,” said Gaspar Tarte, who is spearheading education reform in Panama as the country’s secretary of governmental innovation.”
“We would like to use tools and a methodology that helps children construct knowledge,” Tarte said. “Concept maps was the best tool that we found.”
Related posts:
Comment » | Modeling, Semantic Web
May 16th, 2005 — 12:00am
Thursday night I was at Casablanca in Harvard Square for an information architecture meet and greet after Lou’s Enterprise IA seminar. I ordered a Wolver’s. It was dim and noisy, so after shouting three times and pointing, I ended up with a Wolaver’s…
Not a surprise, right? My first thought was “What’s in my glass?” My second thought – I was surrounded by information architects – was about the semantic angle on the situation. It seems like a fair mistake to make in a loud and crowded bar. But as someone who works there, he should know the environmental context, the ways it affects fundamental tasks like talking and answering questions, and about any alternatives to what he thought I said that are close enough to be easily mistaken. Before I get too far, I’ll point out that I liked the mistake enough to order another.
Setting aside for a moment the notion of a semantically adept agent system that monitors interactions between bartenders and patrons to prevent mistakes like this, let’s look at something more likely, such as how does Google fair with this situation? Some post-socialization research shows that as far as Google is concerned, all roads do in fact lead to Wolaver’s. Even when Google’s results list begins with a link to a page on Wolver’s Ale from the originating brewery, it still suggests that you might want ‘wolaver’s ale’. Maybe this explains the bartender’s mistake.
Here’s the breakdown: Google US suggests “wolaver’s ale” when you search for “wolvers ale” and “wolver’s ale”, but not the other way around. When you search for “Wolavers”, Google suggests the correctly punctuated “Wolaver’s”. You can get to the American ale, but not the British.
More surprising, it’s the same from Google UK, when searching only British pages. (Someone tell me how pages become part of the UK? Maybe when they’re sent off to full-time boarding school?)
Google’s insistence on taking me from wherever I start to “Wolaver’s Ale” comes from more than simple American brew chauvanism. This is what happens when the wrong factors drive decisions about the meanings of things; it’s these basic decisions about semantics that determine whether or not a thing correctly meet the needs of the people looking for answers to a question.
You might say semantic misalignment (or whatever we choose to call this condition) is fine, since Google’s business is aimed at doing something else, but I can’t imagine that business leaderhsip and staff at Wolver’s would be too happy to see Google directing traffic away from them by suggesting that people didn’t want to find them in the first place. Neither Wolver’s nor Wolavers seems to have Google ads running for their names, but what if they did? By now we’re all familar with the fact that googling ‘miserable failure‘ returns a link to the White House web site. This reflects a popularly defined association rich in cultural significance, but that isn’t going to satisfy a paying customer who is losing business because a semantically unaware system works against them.
This a good example of a situation in which intelligent disambiguation based on relationships and inferencing within a defined context has direct business ramifications.
Here’s a preview of the full size table that shows the results of checking some variants of wolvers / wolavers:

Related posts:
Comment » | Semantic Web
April 25th, 2005 — 12:00am
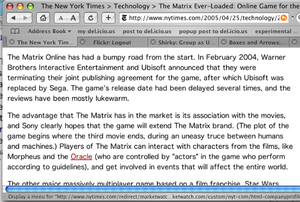
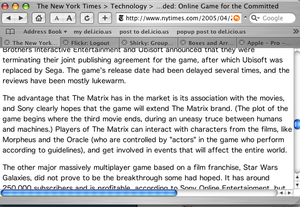
Reading the online edition of the New York Times just before leaving work this afternoon, I came across an ironic mistake that shows the utility of a well developed semantic framework that models the terms and relationships in defingin different editorial contexts. In an article discussing the Matrix Online multiplayer game, text identifying the movie character the Oracle mistakenly linked to a business profile page on the company of the same name. In keeping with the movie’s sinister depictions of technology as a tool for creating deceptive mediated realities, by the time I’d driven home and made mojitos for my visiting in-laws, the mistake was corrected…
Ironic humor aside, it’s unlikely that NYTimes Digital editors intended to confuse a movie character with a giant software company. It’s possible that the NYTimes Digital publishing platform uses some form of semantic framework to oversee automated linking of terms that exist in one or more defined ontologies, in which case this mistake implies some form of mis-categorization at the article level,invokgin the wrong ontology. Or perhaps this is an example of an instance where a name in the real world exists simultaneously in two very different contexts, and there is no semantic rule to govern how the system handles reconciliation of conflicts or invocation of manual intervention in cases when life refuses to fit neatly into a set of ontologies. That’s a design failure in the governance components of the semantic framework itself.
It’s more likely that the publishing platform automatically searches for company names in articles due for publication, and then creates links to the corresponding profile information page without reference to a semantic framework that employs contextual models to discriminate between ambiguous or conflicting term usage. For a major content creator and distributor like the NY Times, that’s a strategic oversight.
In this screen capture, you can see the first version of the article text, with the link to the Oracle page clearly visible:
Mistake:
The new version, without the mistaken link, is visible in this screen capture:
New Version:
Related posts:
Comment » | Semantic Web
February 20th, 2005 — 12:00am
There’s an mSpace demo online.
Related posts:
Comment » | Modeling, Semantic Web, User Experience (UX)
February 18th, 2005 — 12:00am
mSpace is a new framework – including user interface – for interacting with semantically structured information that appeared on Slashdot this morning.
According to the supporting literature, mSpace handles both ontologically structured data, and RDF based information that is not modelled with ontologies.
What is potentially most valuable about the mSpace framework is a useful, usable interface for both navigating / exploring RDF-based information spaces, and editing them.
From the mSpace sourceforge site:
“mSpace is an interaction model designed to allow a user to navigate in a meaningful manner the multi-dimensional space that an ontology can provide. mSpace offers potentially useful slices through this space by selection of ontological categories.
mSpace is fully generalised and as such, with a little definition, can be used to explore any knowledge base (without the requirement of ontologies!).
Please see mspace.ecs.soton.ac.uk for more information.”
From the abstract of the Technical report, titled mSpace: exploring the Semantic Web“
“Information on the web is traditionally accessed through keyword searching. This method is powerful in the hands of a user that is experienced in the domain they wish to acquire knowledge within. Domain exploration is a more difficult task in the current environment for a user who does not precisely understand the information they are seeking. Semantic Web technologies can be used to represent a complex information space, allowing the exploration of data through more powerful methods than text search. Ontologies and RDF data can be used to represent rich domains, but can have a high barrier to entry in terms of application or data creation cost.
The mSpace interaction model describes a method of easily representing meaningful slices through these multidimensional spaces. This paper describes the design and creation of a system that implements the mSpace interaction model in a fashion that allows it to be applied across almost any set of RDF data with minimal reconfiguration. The system has no requirement for ontological support, but can make use of it if available. This allows the visualisation of existing non-semantic data with minimal cost, without sacrificing the ability to utilise the power that semantically-enabled data can provide.”
Related posts:
Comment » | Modeling, Semantic Web, User Experience (UX)
February 18th, 2005 — 12:00am
While researching and evaluating user interfaces and management tools for semantic structures – ontologies, taxonomies, thesauri, etc – I’ve come across or been directed to two good surveys of tools.
The first, courtesy of HP Labs and the SIMILE project is Review of existing tools for working with schemas, metadata, and thesauri. Thanks to Will Evans for pointing this out.
The second is a comprehensive review of nearly 100 ontology editors, or applications offering ontology editing capabilities, put together by Michael Denny at XML.com. You can read the full article Ontology Building: A Survey of Editing Tools, or go directly to the Summary Table of Survey Results.
The original date for this is 2002 – it was updated July of 2004.
Related posts:
Comment » | Modeling, Semantic Web, User Experience (UX)
February 8th, 2005 — 12:00am
rdfdata.org offers a great collection of RDF data sets and services that generate RDF.
Related posts:
Comment » | Semantic Web
February 7th, 2005 — 12:00am
In the latest issue of ACMQueue, Tim Bray is interviewed about his career path and early involvement with the SGML and XML standards. While recounting, Bray makes four points about the slow pace of adoption for RDF, and reiterates his conviction that the current quality of RDF-based tools is an obstacle to their adoption and the success of the Semantic Web.
Here are Bray’s points, with some commentary based on recent experiences with RDF and OWL based ontology management tools.
1. Motivating people to provide metadata is difficult. Bray says, “If there’s one thing we’ve learned, it’s that there’s no such thing as cheap meta-data.”
This is plainly a problem in spaces much beyond RDF. I hold the concept and the label meta-data itself partly responsible, since the term meta-data explicitly separates the descriptive/referential information from the idea of the data itself. I wager that user adoption of meta-data tools and processes will increase as soon as we stop dissociating a complete package into two distinct things, with different implied levels of effort and value. I’m not sure what a unified label for the base level unit construct made of meta-data and source data would be (an asset maybe?), but the implied devaluation of meta-data as an optional or supplemental element means that the time and effort demands of accurate and comprehensive tagging seem onerous to many users and businesses. Thus the proliferation of automated taxonomy and categorization generation tools…
2. Inference based processing is ineffective. Bray says, “Inferring meta-data doesn’t work… Inferring meta-data by natural language processing has always been expensive and flaky with a poor return on investment.”
I think this isn’t specific enough to agree with without qualification. However, I have seen analysis of a number of inferrencing systems, and they tend to be slow, especially when processing and updating large RDF graphs. I’m not a systems architect or an engineer, but it does seem that none of the various solutions now available directly solves the problem of allowing rapid, real-time inferrencing. This is an issue with structures that change frequently, or during high-intensity periods of the ontology life-cycle, such as initial build and editorial review.
3. Bray says, “To this day, I remain fairly unconvinced of the core Semantic Web proposition. I own the domain name RDF.net. I’ve offered the world the RDF.net challenge, which is that for anybody who can build an actual RDF-based application that I want to use more than once or twice a week, I’ll give them RDF.net. I announced that in May 2003, and nothing has come close.”
Again, I think this needs some clarification, but it brings out a serious potential barrier to the success of RDF and the Semantic Web by showcasing the poor quality of existing tools as a direct negative influencer on user satisfaction. I’ve heard this from users working with both commercial and home-built semantic structure management tools, and at all levels of usage from core to occasional.
To this I would add the idea that RDF was meant for interpretation by machines not people, and as a consequence the basic user experience paradigms for displaying and manipulating large RDF graphs and other semantic constructs remain unresolved. Mozilla and Netscape did wonders to make the WWW apparent in a visceral and tangible fashion; I suspect RDF may need the same to really take off and enter the realm of the less-than-abstruse.
4. RDF was not intended to be a Knowledge Representation language. Bray says, “My original version of RDF was as a general-purpose meta-data interchange facility. I hadn’t seen that it was going to be the basis for a general-purpose KR version of the world.”
This sounds a bit like a warning, or at least a strong admonition against reaching too far. OWL and variants are new (relatively), so it’s too early to tell if Bray is right about the scope and ambition of the Semantic Web effort being too great. But it does point out that the context of the standard bears heavily on its eventual functional achievement when put into effect. If RDF was never meant to bear its current load, then it’s not a surprise that an effective suite of RDF tools remains unavailable.
Related posts:
Comment » | Semantic Web, Tools
May 3rd, 2004 — 12:00am
Here’s a some snippets from an article in the Web Services Journal that nicely explains some of the business benefits of a services-based architecture that uses ontologies to integrate disparate applications and knowledge spaces.
Note that XML / RDF / OWL – all from the W3C – together only make up part of the story on new tools for how making it easy for systems (and users, and businesses…) to understand and work with complicated information spaces and relationships. There’s also Topic Maps, which do a very good job of visually mapping relationships that people and systems can understand.
Article:Semantic Mapping, Ontologies, and XML Standards
The key to managing complexity in application integration projects
Snippets:
Another important notion of ontologies is entity correspondence. Ontologies that are leveraged in more of a B2B environment must leverage data that is scattered across very different information systems, and information that resides in many separate domains. Ontologies in this scenario provide a great deal of value because we can join information together, such as product information mapped to on-time delivery history mapped to customer complaints and compliments. This establishes entity correspondence.
So, how do you implement ontologies in your application integration problem domain? In essence, some technology – either an integration broker or applications server, for instance – needs to act as an ontology server and/or mapping server.
An ontology server houses the ontologies that are created to service the application integration problem domain. There are three types of ontologies stored: shared, resource, and application. Shared ontologies are made up of definitions of general terms that are common across and between enterprises. Resource ontologies are made up of definitions of terms used by a specific resource. Application ontologies are native to particular applications, such as an inventory application. Mapping servers store the mappings between ontologies (stored in the ontology server). The mapping server also stores conversion functions, which account for the differences between schemas native to remote source and target systems. Mappings are specified using a declarative syntax that provides reuse.
RDF uses XML to define a foundation for processing metadata and to provide a standard metadata infrastructure for both the Web and the enterprise. The difference between the two is that XML is used to transport data using a common format, while RDF is layered on top of XML defining a broad category of data. When the XML data is declared to be of the RDF format, applications are then able to understand the data without understanding who sent it.
Comment » | Semantic Web