Tag Clouds Evolve: Understanding Tag Clouds
Zeldman jokingly called tag clouds “the new mullets” last year. At the time, I think he was taken a bit by surprise by the rapid spread of the tag cloud (as many people were). A big year later, it looks like this version of the world’s favorite double duty haircut will stay in fashion for a while. Zeldman was discussing the first generation of tag clouds. I have some ideas on what the second generation of tag clouds may look like that will conclude this series of two essays. These two pieces combine ideas brewing since the tagging breakout began in earnest this time last year, with some predictions based on recent examples of tag clouds in practice.
Update: Part two of this essay, Second Generation Tag Clouds, is available.
This first post lays groundwork for predictions about the second generation of tag clouds by looking at what’s behind a tag cloud. I’ll look at first generation tag clouds in terms of their reliance on a “chain of understanding” that semantically links groups of people tagging and consuming tags, and thus underlies tagging and social metadata efforts in general. I’ll begin with structure of first generation tag clouds, and move quickly to the very important way that tag clouds serve as visualizations of semantic fields.
Anatomy of a Tag Cloud
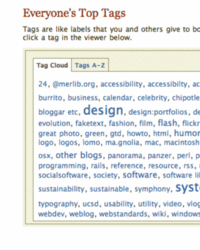
Let’s begin with the familiar first generation tag cloud. Tag clouds (here we’re talking about the user experience, and not the programmatic aspects) commonly consist of two elements: a collection of linked tags shown in varying fonts and colors to indicate frequency of use or importance, and a title to indicate the context of the collection of tags. Flickr’s tags page is the iconic example of the first generation tag cloud. Screen shots of several other well known tag cloud implementations show this pattern holding steady in first generation tagging implementations such as del.icio.us and technorati, and in newer efforts such as last.fm and ma.gnolia.
Wikipedia’s entry for tag cloud is quite similar, reading, “A tag cloud (more traditionally known as a weighted list in the field of visual design) is a visual depiction of content tags used on a website. Often, more frequently used tags are depicted in a larger font or otherwise emphasized, while the displayed order is generally alphabetical… Selecting a single tag within a tag cloud will generally lead to a collection of items that are associated with that tag.”
In terms of information elements and structure, first generation tag clouds are low complexity. Figure 1 shows a schematic view of a first generation tag cloud. Figures 2 through 5 are screenshots of well-known first generation tag clouds.
Figure 1: Tag Cloud Structure

Figure 2: last.fm

Figure 3: technorati

Figure 4: del.icio.us

Figure 5: Ma.gnolia
Tag Clouds: Visualizations of Semantic Fields
The simple structure of first generation tag clouds allows them to perform a very valuable function without undue complexity. That function is to visualize semantic fields or landscapes that are themselves part of a chain of understanding linking taggers and tag consumers. This is a good moment to describe the “chain of understanding”. The “chain of understanding” is an approach I use to help identify and understand all the different kinds of people and meaning, and the transformations and steps involved in passing that meaning on, that must work and connect properly in order for something to happen, or an end state to occur. The chain of understanding is my own variation / combination of common cognitive and information flow mapping using a scenario style format. I’ve found the term resonates well with clients and other audiences outside the realm of IA.
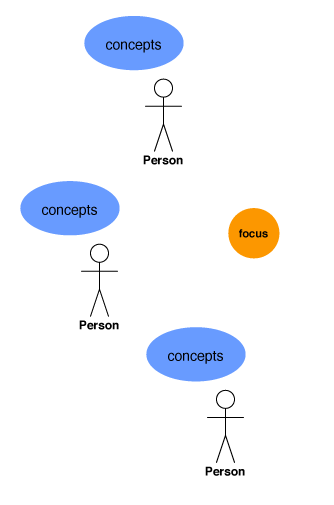
How does the chain of understanding relate to tag clouds? The tags in tag clouds originate directly from the perspective and understanding of the people tagging, but undergo changes while becoming a tag cloud. (For related reading, see Rashmi Sinha’s A social analysis of tagging which examines some of the social mechanisms underlying the activity of tagging.) Tag clouds accrete over time when one person or a group of people associate a set of terms with a focus of some sort; a photo on flickr, a URL / link in the case of del.icio.us, an album or song for last.fm. As this list shows, a focus can be anything that can carry meaning or understanding. The terms or tags serve as carriers and references for the concepts each tagger associates with the focus. Concepts can include ideas of aboutness, origin, or purpose, descriptive labels, etc. While the concepts may change, the focus remains stable.
What’s key is that the tag is a reference and connection to the concept the tagger had in mind. This connection requires an initial understanding of the focus itself (perhaps incorrect, but still some sort of understanding), and the concepts that the tagger may or may not choose to associate with the focus. And this is the first step in the chain of understanding behind tag clouds, as shown in Figure 6.
Figure 6: Origin: Focus and Concepts
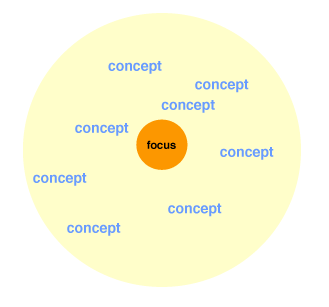
As a result, tag clouds are more than collection of descriptive or administrative terms attached to a link, or other sort of focus. The tag is a sort of label that references a concept or set of concepts. A cloud of tags is then a collection of labels referring to a cluster of aggregated concepts. The combination of tags that refer to concepts, with the original focus, creates a ‘semantic field’. A semantic field is the set of concepts connected to a focus, but in a form that is now independent of the originating taggers, and available to other people for understanding. In this sense, a semantic field serves as a form of reified understanding that the taggers themselves – as well as others outside the group that created the semantic field – can now understand, act on, etc. (This speaks to the idea that information architecture is a discipline strongly aimed at reification, but that’s a different discussion…). Figure 7 shows this second step in the chain of understanding; without it, there is no semantic field, and no tag cloud can form. And now because this post is written from the viewpoint of practical implications for tag cloud evolution, I’m going to hold the definition and discussion of a semantic field and focus, before I wander off track into semiotics, linguistics, or other territories. The most important thing to understand is that *tag clouds comprise visualizations of a semantic field*, as we’ve seen from the chain of understanding.
Figure 7: Semantic Field
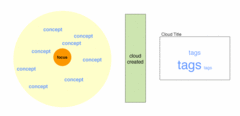
I believe tag clouds are revolutionary in their ability to translate the concepts associated with nearly anything you can think of into a collectively visible and actionable information environment, an environment that carries considerable evidence of the original understandings that precede and inform it. In a practical information architecture sense, tag clouds can make metadata – one of the more difficult and abstract of the fundamental concepts of the digital universe for the proverbial person on the street – visible in an easily understood fashion. The genius of tag clouds is to make semantic concepts, the frames of understanding behind those concepts, and their manifestation as applied metadata tangible for many, many people.
Figure 8: Semantic Field As Tag Cloud
With this notion of a tag cloud as a visualization of a semantic field in mind, let’s look again at an example of a tag cloud in practice. The flickr style tag cloud (what I call a first generation tag cloud) is in fact a visualization of many tag separate clouds aggregated together. Semantically then, the flickr tag cloud is the visualization of the cumulative semantic field accreted around many different focuses, by many people. In this usage, the flickr tag cloud functions as a visualization of a semantic landscape built up from all associated concepts chosen from the combined perspectives of many separate taggers.
To summarize, creating a tag cloud requires completion of the first three steps of the chain of understanding that supports social metadata. Those steps are:
1. Understanding a focus and the concepts that could apply that focus
2. Accumulating and capturing a semantic field around the focus
3. Visualizing the semantic field as a tag cloud via transformation
The fourth step in this chain involves users’ attempts to understand the tag cloud. For this we must introduce the idea of context, which addresses the question of which original perspectives underlie the semantic field visualized in a tag cloud, and how those concepts have changed before or during presentation.
How Cloud Consumers Understand Tag Clouds
Users need to put a given tag cloud in proper context in order to understand the cloud effectively. Their end may goals may be finding related items, surveying the thinking within a knowledge domain, identifying and contacting collaborators, or some other purpose, but it’s essential for them to understand the tags in the cloud to achieve those goals. Thus whenever a user encounters a tag cloud, they ask and answer a series of questions intended to establish the cloud’s context and further their understanding. Context related questions often include “Where did these tags come from? Who applied them? Why did they choose these tags, and not others? What time span does this tag cloud cover?” Context in this case means knowing enough about the conditions and environment from which the cloud was created, and the decisions made about what tags to present and how to present them. Figure 9 summarizes the idea of context.
Figure 9: Cloud Context

Once the user or consumer places the tag cloud in context, the chain of understanding is complete, and they can being to use or work with the tag cloud. Figure 10 shows the complete chain of understanding we’ve examined.
Figure 10 Chain of Understanding

In part two, titled “Second Generation Tag Clouds”, I’ll share some thoughts on likely ways that the second generation of tag clouds will evolve in structure and usage in the near future, based on how they support a chain of understanding that semantically links taggers and tag cloud consumers. Context is the key for tag cloud consumers, and we’ll see how it affects the likely evolution of the tag cloud as a visualization tool.
Update: Part two Second Generation Tag Clouds is available


{kind=link}