During 2006, tag clouds moved beyond their well-known role as navigation mechanisms and indicators of activity within social media experiences, emerging as a standard visualization technique for texts and textual data in general.
This use of tag clouds does not commonly involve tags, social networks, emergent architectures, folksonomies, or metadata.
“Text cloud” might be a more accurate label for these visualizations than tag cloud. In addition to recognizing fundamental differences – text clouds differ from tag clouds in composition (no tags at all) and purpose (predominantly comprehension, rather than access or navigation) – distinguishing the two types of clouds will make it much easier to assess their abilities to support user experience needs and business goals.
The emergence of this new form of text cloud looks like a good example of speciation in action (though it’s too early to tell whether the end result will be cladogenesis or anagenesis).
Major and minor publications feature(d) text clouds as visualizations in 2006, both permanently and temporarily:
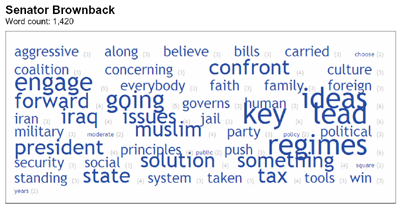
The Economist’s Text cloud

In 2006, several free and public tools for generating text clouds locally on the desktop or via a service available through the Web were released. The increase in the number and variety of specific text cloud tools reflects embrace and enthusiasm for text clouds in communities of interest for information visualization, language processing, and semantics.
Some of the better known examples of text cloud tools include:
The Many Eyes Cloud

The text clouds created with these tools range across a wide spectrum of speeches and writing:
Text clouds are meant to facilitate rapid understanding and comprehension of a body of words, links, phrases, etc. Any block of information composed of text is open to analysis as a text cloud, as these screen captures of text clouds for restaurant menus, ingredients, wikipedia, magazine covers, and even poems demonstrate.
Tim O’Reilly uses text clouds for a number of purposes:
We used them a bunch to analyze the topics, companies and people at the last FOO Camp, and they were the most useful of the visualizations we did. They helped us see where we were under- and over-represented in terms of companies and particular technologies we were wanting to explore. …So they have many uses beyond just showing what we normally think of as tags.
Non-linear Access
The emergence of text clouds shows continuing exploration and refinement of cloud style displays as a new form of user interface, adapted to specific contexts. Continued refinement of text clouds in this direction may indicate an expanding role for commonly available and sophisticated text visualization tools to support specialized goals for information display and understanding.
Remember that Google is busy right now scanning thousands of books per day from several of the world’s major academic libraries, as part of it’s self-appointed labor of organizing the world’s information. That’s a lot of new text. How will people work with effectively with such an overwhelming amount of text, of so many different kinds, from so many different sources?
Consider the following, from Ulysses’ Without Guilt by Stacy Schiff (in the New York Times):
Recently Cathleen Black, president of Hearst Magazines, urged a group of publishing executives to think of their audience as consumers rather than readers. She’s onto something: arguably the very definition of reading has changed. So Google asserts in defending its right to scan copyrighted materials. The process of digitizing books transforms them, the company contends, into something else; our engagement with a text is different when we call it up online. We are no longer reading. We’re searching – a function that conveniently did not exist when the concept of copyright was established.
On a larger scale, the growing use of text clouds hints at a (potential) deeper cultural shift in the way we go about reading and comprehension: a shift from linear modes based on reading words and sentences, to nonlinear modes based on viewing summaries of content in aggregate as a way of discovering concepts and patterns. (Finally, a legitimate use for Twitter…) Experimenting with text clouds for non-linear reading and comprehension (now that’s a sexy term…) is a natural evolution of the role cloud style displays play as an alternative / compliment / supplement to the list based navigation now dominant in user experiences.
A Text Cloud of Twitter Posts (A TwitterCloud?)
ago applied assuming bad briela classes clean coke decompressing dhowell dinner drinkin eisenbear full ga god guy half happy house ibterri impressing issues jedi joanna knows less lhalff lost minute moment nybble ohhhhh rfk rum ryanjames scholarship seconds sites skiing status summer twitterrific txt tyguy umpteenth vlu77 watched water web created at TagCrowd.com
I’m not predicting the end of reading as we know it, nor the end of navigation as we know it: both will be with us for a long, long time. But I do believe that text clouds might constitute an emerging method for augmenting comprehension and display of text, with broad potential uses.
Enterprising Clouds
What about someone lacking time to fully read a Shakespeare play, or a faddish business book, but who needs to understand something about that book’s meaning and substance? A text cloud creation tool could extract the most commonly mentioned terms, and otherwise profile the words that make up the text. It would be risky to rely on a shallow text cloud (and Tim O’Reilly mentions this specifically) for deep comprehension, but it would be enough to understand the concepts that appear, and allow polite conversation at a networking event, or lunch with that certain manager who recommended the book.
If I were entrepreneurial, I’d source a set of free electronic versions of classic texts, process them with one of the free text cloud tools, apply some XSLT and other transformations to generate consistent readable formatting, and sell the results as a line of ebooks called “Cloud Notes”. Of course, someone’s beaten me to it already…
What’s in store for the future?
In this fashion, text clouds may become a generally applied tool for managing growing information overload by using automated synthesis and summarization. In the information saturated future (or the information saturated present), text clouds are the common executive summary on steroids and acid simultaneously; assembled with muscular syntactical and semantic processing, and fed to reading-fatigued post-literates as swirling blobs of giant words in wild colors, it consists of signifiers for reified concepts that tweak the eye-brain-language conduit directly.