April 25th, 2005 — 12:00am
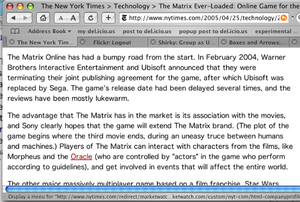
Reading the online edition of the New York Times just before leaving work this afternoon, I came across an ironic mistake that shows the utility of a well developed semantic framework that models the terms and relationships in defingin different editorial contexts. In an article discussing the Matrix Online multiplayer game, text identifying the movie character the Oracle mistakenly linked to a business profile page on the company of the same name. In keeping with the movie’s sinister depictions of technology as a tool for creating deceptive mediated realities, by the time I’d driven home and made mojitos for my visiting in-laws, the mistake was corrected…
Ironic humor aside, it’s unlikely that NYTimes Digital editors intended to confuse a movie character with a giant software company. It’s possible that the NYTimes Digital publishing platform uses some form of semantic framework to oversee automated linking of terms that exist in one or more defined ontologies, in which case this mistake implies some form of mis-categorization at the article level,invokgin the wrong ontology. Or perhaps this is an example of an instance where a name in the real world exists simultaneously in two very different contexts, and there is no semantic rule to govern how the system handles reconciliation of conflicts or invocation of manual intervention in cases when life refuses to fit neatly into a set of ontologies. That’s a design failure in the governance components of the semantic framework itself.
It’s more likely that the publishing platform automatically searches for company names in articles due for publication, and then creates links to the corresponding profile information page without reference to a semantic framework that employs contextual models to discriminate between ambiguous or conflicting term usage. For a major content creator and distributor like the NY Times, that’s a strategic oversight.
In this screen capture, you can see the first version of the article text, with the link to the Oracle page clearly visible:
Mistake:
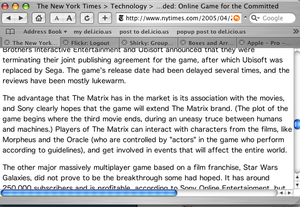
The new version, without the mistaken link, is visible in this screen capture:
New Version:
Related posts:
Comment » | Semantic Web
April 20th, 2005 — 12:00am
The April issue of D-Lib Magazine includes a two-part Survey of social bookmarking tools.
Social bookmarking is on the collective brain – at least for the moment -and most of those writing about it choose to take one or more positions for, against, or orthogonal to its various aspects. Here’s the position of the D-Lib survey authors:
“Despite all the current hype about tags – in the blogging world, especially – for the authors of this paper, tags are just one kind of metadata and are not a replacement for formal classification systems such as Dublin Core, MODS, etc. [n15]. Rather, they are a supplemental means to organize information and order search results.”
This is — no surprise from “a solely electronic publication with a primary focus on digital library research and development, including but not limited to new technologies, applications, and contextual social and economic issues” — the librarians’ view, succinctly echoed by Peter Morville in his presentation during the panel ‘Sorting Out Social Classification’ at this year’s Information Architecture summit.
The D-Lib authors’ assessment dovetails nicely with Peter’s views on The Speed of Information Architecture from 2001, and it shows how library science professionals may decide to place social bookmarking in relation to the larger context of meta-data lifecycles; a realm they’ve known and inhabited for far longer than most people have used Flickr to tag their photos.
I found some of the authors’ conclusions more surprising. They say, “In many ways these new tools resemble blogs stripped down to the bare essentials.” I’m not sure what this means; stripped-down is the sort of term that usually connotes a minimalist refactoring or adaptation that is designed to emphasize the fundamental aspects of some original thing under interpretation, but I don’t think they want readers to take away the notion that social bookmarking is an interpretation of blogging.
Moving on, they say, “Here the essential unit of information is a link, not a story, but a link decorated with a title, a description, tags and perhaps even personal recommendation points.” which leaves me wondering why it’s useful to compare Furl to blogging?
A cultural studies professor of mine used to say of career academics, “We decide what things mean for a living”. I suspect this is what the D-Lib authors were working toward with their blogging comparison. Since the label space for this thing itself is a bit crowded (contenders being ethnoclassification, folksonomy, social classification), it makes better sense to elevate the arena of your own territorial claim to a higher level that is less cluttered with other claimants, and decide how it relates to something well-known and more established.
They close with, “It is still uncertain whether tagging will take off in the way that blogging has. And even if it does, nobody yet knows exactly what it will achieve or where it will go – but the road ahead beckons.”
This is somewhat uninspiring, but I assume it satisfies the XML schema requirement that every well-structured review or essay end with a conclusion that opens the door to future publications.
Don’t mistake my pique at the squishiness of their conclusions for dis-satisfaction with the body of the survey; overall, the piece is well-researched and offers good context and perspective on the antecedents of and concepts behind their subject. Their invocation of Tim O’Reilly’s ‘architectures of participation’ is just one example of the value of this survey as an entry point into related phenomena.
Another good point the D-Lib authors make is the way that the inherent locality, or context-specificity, of collections of social bookmarks allows them to provide higher-quality pointers to resources relevant for specialized purposes than the major search engines, which by default index globally, or without an editorial perspective.
Likely most useful for the survey reader is their set of references, which taps into the meme flow for social bookmarking by citing a range of source conversations, editorials, and postings from all sides of the phenomenon.
Related posts:
Comment » | Social Media
April 2nd, 2005 — 12:00am
David Brooks Op-Ed column The Art of Intelligence in today’s NY Times is strongly relevant to questions of user research method, design philosophy, and understanding user experiences.
Brooks opens by asserting that that US Intelligence community shifted away from qualitative / interperative research and analysis methods to quantitative research and analysis methods during the 60’s in an attempt to legitimize conclusions in the fashion of the physical sciences. From this beginning, Brooks’ conclusion is that the basic epistemological shift in thought about what sorts of information are relevant to understanding the needs and views of groups of people (nations, societies, political leadership circles) yielded interpretations of their views and plans which were either useless or incorrect, models which then lead decision makers to a series of dramatic policy errors – examples of which we still see to this day.
Brooks contrasts the “unimaginative” quantitative interpretations assembled by statistical specialists with the broad mix of sources and perspectives which cultural and social thinkers in the 50’s used to understand American and other societies in narrative, qualitative ways.
According to Brooks, narrative, novelistic ways of understanding provided much better – more insightful, imaginative, accureate, and useful – advice on how Americans and others understood the world, opening the way to insight into strategic trends and opportunities. I’ve read many of the books he uses as examples – they’re some of the classics on social / cultural / historical reading lists – of the qualitative tradition, and taken away vivid pictures of the times and places they describe that I use to this day when called on to provide perspective on those environments.
Perhaps it’s implied, but what Brooks doesn’t mention is the obvious point that both approaches – qualitative and quantitative – are necessary to crafting fully-dimensioned pictures of people. Moving explicitly to the context of user research, qualitative analysis can tell us what people want or need or think or feel, but numbers give specific answers regarding things like what they’re willing or able to spend, how much time they will invest in trying to find a piece of information, or how many interruptions they will tolerate before quitting a task in frustration.
When a designer must choose between interaction patterns, navigation labels, product imagery, or task flows, they need both types of understanding to make an informed decision.
Some excerpts from Brooks’ column:
“They relied on their knowledge of history, literature, philosophy and theology to recognize social patterns and grasp emerging trends.”
This sounds like a strong synthetic approach to user research.
“I’ll believe the system has been reformed when policy makers are presented with competing reports, signed by individual thinkers, and are no longer presented with anonymous, bureaucratically homogenized, bulleted points that pretend to be the product of scientific consensus.”
“But the problem is not bureaucratic. It’s epistemological. Individuals are good at using intuition and imagination to understand other humans. We know from recent advances in neuroscience, popularized in Malcolm Gladwell’s “Blink,” that the human mind can perform fantastically complicated feats of subconscious pattern recognition. There is a powerful backstage process we use to interpret the world and the people around us.”
“When you try to analyze human affairs using a process that is systematic, codified and bureaucratic, as the CIA does, you anesthetize all of these tools. You don’t produce reason – you produce what Irving Kristol called the elephantiasis of reason.”
Related posts:
Comment » | User Research